
大型电商直播APP开发关于上网日志数据处理方法,大型直播APP软件开发SDK通过手机摄像头和麦克风直接采集音视频数据。其中,视频采样数据一般采用RGB或YUV格式、音频采样数据一般采用PCM格式。采集到的原始音视频的体积是非常大的,需要经过压缩技术处理来提高传输效率。为了便于手机视频的推流、拉流以及存储,通常采用视频编码压缩技术来减少视频的体积,现在比较常用的视频编码是H.264。在音频方面,比较常用的是AAC编码格式,其它如MP3、WMA也是可选方案。视频经过编码压缩大大提高了视频的存储和传输效率,当然,经过压缩后的视频在播放时必须进行解码。所以对于数据日志的处理就显得尤为重要,APP开发公司总结它们通常在各种元素的特定要求上有很大的相似性的流程上网日志数据处理方法的流程如下:

1.对上网日志数据的URL地址进行提取。
2.对已知的URL数据,按照基准URL分类准则进行分类。
3.对未知的URL地址,首先爬取网页数据,然后对爬取的网页数据按照网页分类模型,进行网页分类,不断优化模型,提高网页分类的准确性。4.根据每个人访问网址和对应网址的网页分类,利用模型统计出每个手机号码的个人喜好,为精准营销提供依据。具体流程如下图所示。
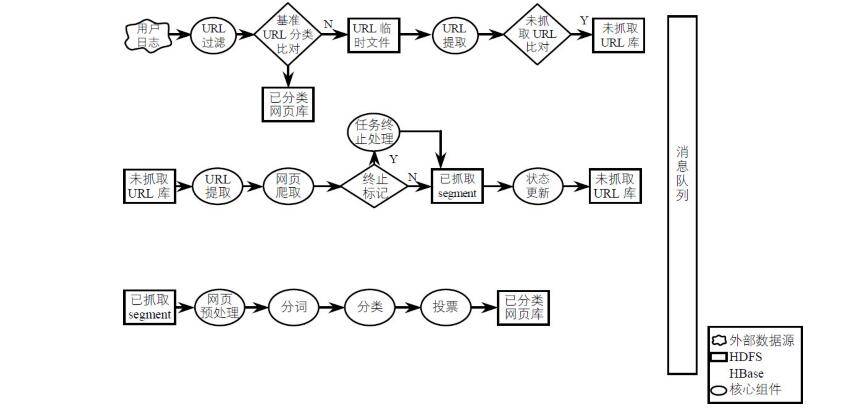
1.对上网日志数据的URL地址进行提取。
2.对已知的URL数据,按照基准URL分类准则进行分类。
3.对未知的URL地址,首先爬取网页数据,然后对爬取的网页数据按照网页分类模型,进行网页分类,不断优化模型,提高网页分类的准确性。4.根据每个人访问网址和对应网址的网页分类,利用模型统计出每个手机号码的个人喜好,为精准营销提供依据。具体流程如下图所示。
大型电商APP开发关于上网日志系统的技术架构方案
基于上述处理流程,上网日志处理系统的逻辑架构方案如下图所示。
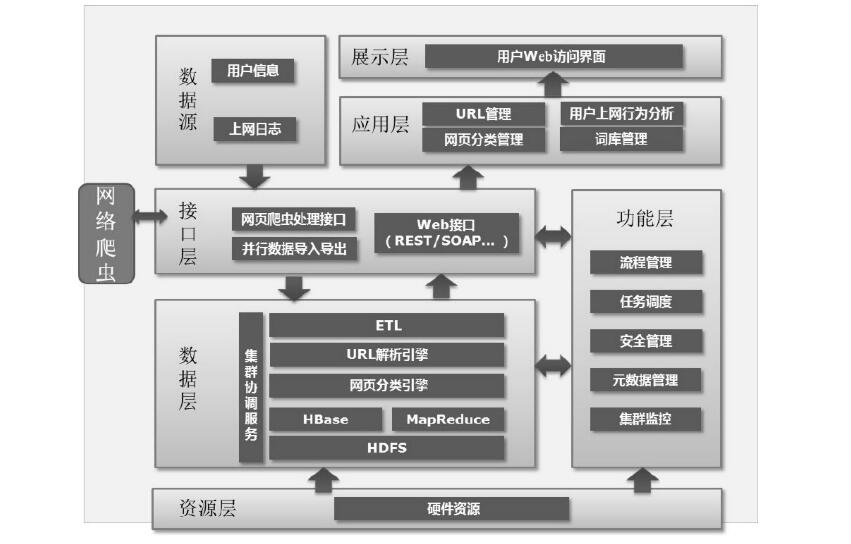
针对每一部分的具体功能介绍如下。数据源从电信运营商系统服务器定时获取用户基本信息和上网日志信息,输入到集群HDFS文件系统和HBase数据库中。
基于上述处理流程,上网日志处理系统的逻辑架构方案如下图所示。
针对每一部分的具体功能介绍如下。数据源从电信运营商系统服务器定时获取用户基本信息和上网日志信息,输入到集群HDFS文件系统和HBase数据库中。
接口层负责与外部系统的数据进行交换,包括用户数据、上网日志数据的采集,互联网网页内容的爬取和对外围系统提供访问接口。数据接口可实现对关系型数据库,如Oracle、DB2等的数据交换,包括采集和加载过程,同时也支持文件类型的数据,可以通过FTP等方式进行采集。系统对外提供统一访问接口,具有开放性、高性能、可监控管理和安全性等特征。
数据层是分布式大数据处理平台,从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据模型,将数据加载到分布式存储中去。通过分布式计算框架可以实现数据的清洗、转换、校验和装载等过程。资源层由于分布式架构带来的硬件部署的复杂度,需要对物理资源层和系统平台层提供进一步的抽象,以提供自动化部署和弹性的运维能力,因此资源层实现了对物理资源的自动部署和动态扩展,对分布式集群中不同角色进行灵活部署。
功能层实现了数据处理流程模块的模块化处理,提供集群的访问控制,并负责Hadoop集群的运行管理和系统报警日志管理。数据处理能够进行任意串并联的流程调度,并且能够控制节点的优先级、超时时间、重试次数,同时具备路由判断能力,能够在多分支的情况下通过条件进行不同的流程流转。采用异步调度策略,能够支持大并发量的调度。应用层负责应用功能的具体算法实现。实现了大型电商APP网页分类索引,通过互联网注册URL及其类别的爬取,对数据进行统一管理,并置于持久化存储中。将其中的类别进行模块化重组,划分至对应的层次结构,如(社交-社区)或(社交-微博),对类别进行索引。
实现了词库分类管理,通过对网络热门词汇及常用词汇的爬取,根据所属类别构建分词词库。词库定期更新,不断完善。实现了用户行为统一分析,基于客户的访问行为,识别其偏好特征,根据内容偏好特征进行客户细分,并支持目标客户群提取,以便支撑营销活动,实现了URL地址统一管理。展示层负责将应用功能处理结果通过Web页面展示,并且提供交互页面,熟练使用各种应用处理功能,并对处理结果进行动态展示。网络爬虫负责从互联网系统中爬取网页的具体内容信息。具体处理流程是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。程序从日志文件中提取URL地址,并进行过滤、去重操作。其中过滤操作去除图片、视频、软件等内容的URL地址;去重会把重复的URL、已经抓取的URL、已经分类的URL地址去掉。剩下的URL地址送入爬虫的地址库中,爬虫会根据一定的规则产生要抓取的URL地址,然后通过MapReduce的方式并发抓取产生的URL地址,最终把抓取到的URL地址的内容存储到HDFS文件系统中。由于网络爬取流程需要互联网资源支持,数据处理Hadoop集群是和电信运营商内部网络互联,而且Hadoop集群的安全处理措施不够完善,因此,它们之间的访问需要严格控制,以保证网络部署安全。在物理架构设计上,需要设计两个完整的内部集群网络,集群网络之间需要用防火墙进行访问控制。大型电商APP开发关于程序系统上网日志处理系统的物理网络部署拓扑如下图所示。好了,深圳APP开发公司本文关于“大型电商直播APP开发关于上网日志数据处理方法”的知识就分享到这里,谢谢关注,博纳网络编辑整理。
功能层实现了数据处理流程模块的模块化处理,提供集群的访问控制,并负责Hadoop集群的运行管理和系统报警日志管理。数据处理能够进行任意串并联的流程调度,并且能够控制节点的优先级、超时时间、重试次数,同时具备路由判断能力,能够在多分支的情况下通过条件进行不同的流程流转。采用异步调度策略,能够支持大并发量的调度。应用层负责应用功能的具体算法实现。实现了大型电商APP网页分类索引,通过互联网注册URL及其类别的爬取,对数据进行统一管理,并置于持久化存储中。将其中的类别进行模块化重组,划分至对应的层次结构,如(社交-社区)或(社交-微博),对类别进行索引。
实现了词库分类管理,通过对网络热门词汇及常用词汇的爬取,根据所属类别构建分词词库。词库定期更新,不断完善。实现了用户行为统一分析,基于客户的访问行为,识别其偏好特征,根据内容偏好特征进行客户细分,并支持目标客户群提取,以便支撑营销活动,实现了URL地址统一管理。展示层负责将应用功能处理结果通过Web页面展示,并且提供交互页面,熟练使用各种应用处理功能,并对处理结果进行动态展示。网络爬虫负责从互联网系统中爬取网页的具体内容信息。具体处理流程是一种按照一定的规则,自动抓取万维网信息的程序或者脚本。程序从日志文件中提取URL地址,并进行过滤、去重操作。其中过滤操作去除图片、视频、软件等内容的URL地址;去重会把重复的URL、已经抓取的URL、已经分类的URL地址去掉。剩下的URL地址送入爬虫的地址库中,爬虫会根据一定的规则产生要抓取的URL地址,然后通过MapReduce的方式并发抓取产生的URL地址,最终把抓取到的URL地址的内容存储到HDFS文件系统中。由于网络爬取流程需要互联网资源支持,数据处理Hadoop集群是和电信运营商内部网络互联,而且Hadoop集群的安全处理措施不够完善,因此,它们之间的访问需要严格控制,以保证网络部署安全。在物理架构设计上,需要设计两个完整的内部集群网络,集群网络之间需要用防火墙进行访问控制。大型电商APP开发关于程序系统上网日志处理系统的物理网络部署拓扑如下图所示。好了,深圳APP开发公司本文关于“大型电商直播APP开发关于上网日志数据处理方法”的知识就分享到这里,谢谢关注,博纳网络编辑整理。
当前文章链接:/construction/appkaifa/14416.html
如果您觉得案例还不错请帮忙分享:
[声明]本网转载网络媒体稿件是为了传播更多的信息,此类稿件不代表本网观点,本网不承担此类稿件侵权行为的连带责任。故此,如果您发现本网站的内容侵犯了您的版权,请您的相关内容发至此邮箱【qin@198bona.com 】,我们在确认后,会立即删除,保证您的版权。